汽车行业精准营销分析案例
案例介绍
1. 案例背景
在互联网逐渐步入大数据时代后,不可避免的为企业及消费者行为带来一系列改变与重塑。其中最大的变化莫过于,消费者的一切行为在企业面前似乎都将是“可视化”的。随着大数据技术的深入研究与应用,企业的专注点日益聚焦于怎样利用大数据来为精准营销服务,进而深入挖掘潜在的商业价值。
随着互联网技术的迅速发展,消费者热衷于网上购物的越来越多,消费者已进入到了互联网时代,了解消费者行为意愿,有利于改进电商运营的对策,促进电商的全面发展,满足消费者的需求,实现电商发展的目标。由此可见,精准营销对于商家的重要性。
精准营销借助先进的大数据技术、网络通讯技术及现代高度分散物流等手段保障和顾客的长期个性化沟通,使营销达到可度量、可调控等精准要求。摆脱了传统广告沟通的高成本束缚,使企业低成本快速增长成为可能。
通过对消费者的消费行为的精准衡量和分析,建立相应的数据体系,通过数据分析进行客户优选,使营销效益达到最大化。
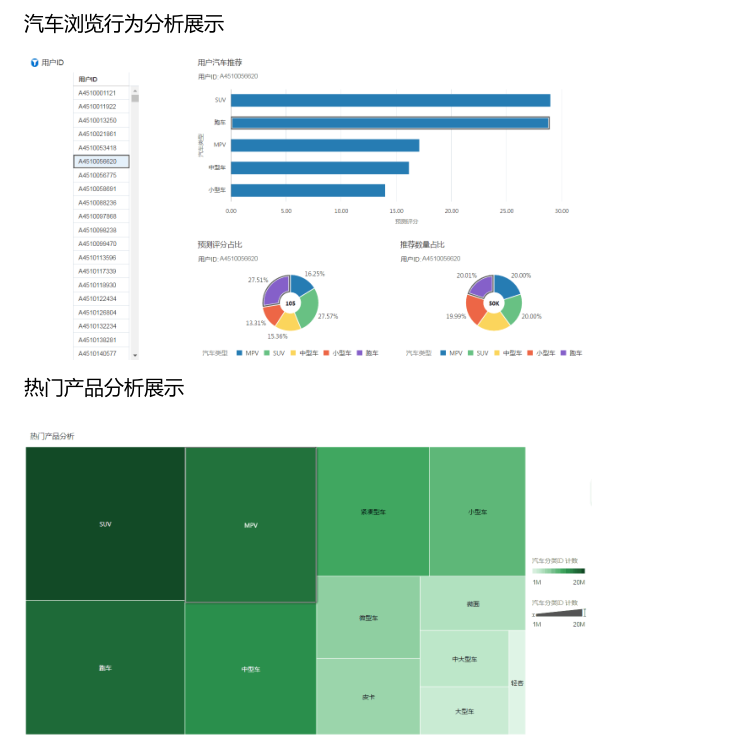
通过大数据分析精准定位目标用户及目标关注产品,提高销售成功几率并减少原有对非目标客户的营销投入成本。
通过大数据分析手段,对用户浏览数据进行分析,得到热门汽车产品信息。
获取用户上网浏览数据,分析得到用户汽车浏览数据信息。
数据名称 | 数据来源 |
用户上网行为数据 | 电信公司 |
汽车产品配置数据 | 互联网采集 |
FTP是用于在网络上进行文件传输的一套标准协议,使用客户/服务器模式。它属于网络传输协议的应用层。能操作任何类型的文件而不需要进一步处理。用户可以通过一个支持FTP协议的客户机程序,连接到在远程主机上的FTP服务器程序。通过客户机程序向服务器程序发出命令,服务器程序执行用户所发出的命令,并将执行的结果返回到客户机(如上传、下载等操作)。
Apache Spark是专为大规模数据处理而设计的快速通用的计算引擎。Spark拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是——Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。
在本案例中使用Spark进行数据处理及机器学习。使用相同的技术进行数据处理工程衔接更好,更方便。
Oracle数据可视化(Data Visualization)。利用直观的数据可视化和交互式的自助探索,来透视企业的业务绩效,从而有机会快速的对业务展开持续的洞察和改善。现在,越来越多的人们开始利用数据可视化技术来探查数据,并得出与以往截然不同的新洞察。OracleDV的优势是在方便用户使用、加速交互性的同时,保证数据的准确性和一致性。拥有丰富的可视化控件。加载数据,或者混搭不同来源的数据,以拖拽的方式进行交互性探索。只需要通过点击,就可以快速地检索数据,找到更多的答案和业务洞察。
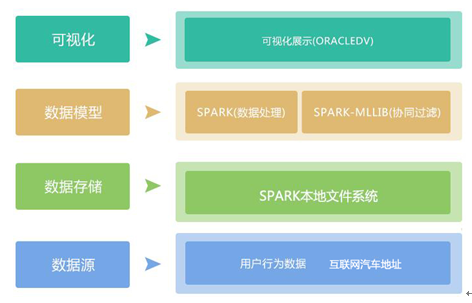
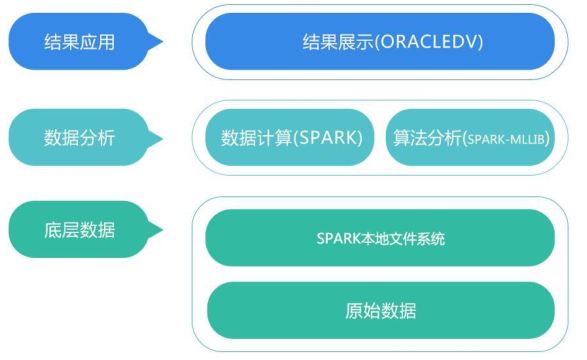
数据采集:FTP
数据处理:Spark
机器学习:Spark
可视化:OracleDV
协同过滤ALS模型:协同过滤是利用集体智慧的一个典型方法。算法通过对用户历史行为数据的挖掘发现用户的偏好,基于不同的偏好对用户进行群组划分并推荐品味相似的商品。基于用户的协同过滤算法是通过用户的历史行为数据发现用户对商品或内容的喜欢(如商品购买,收藏,内容评论或分享),并对这些喜好进行度量和打分。根据不同用户对相同商品或内容的态度和偏好程度计算用户之间的关系。在有相同喜好的用户间进行商品推荐,并预测对推荐产品的喜好度量值。简单的说就是如果A,B两个用户都购买了x,y,z三本图书,并且给出了5星的好评。那么A和B就属于同一类用户。可以将A看过的图书w也推荐给用户B。
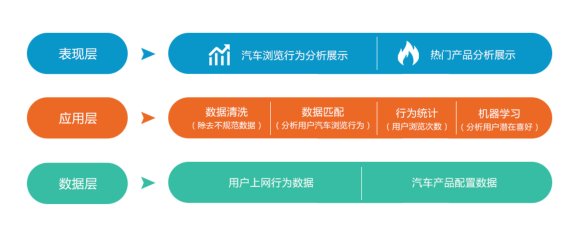
URL采集、汽车信息采集、数据清洗、数据匹配、行为统计、机器学习、数据可视化
汽车行业精准营销案例,是通过用户上网行为数据与汽车产品数据进行关联,识别用户汽车类访问数据并换算其对应的喜欢程度(评分)。通过机器学习模型分析用户潜在喜欢产品。具体步骤如下:
URL采集:通过FTP从将用户上网行为数据从采集服务器下载到本地。
汽车信息采集:通过爬虫采集互联网汽车信息数据。
清洗:通过Spark对URL数据进行清洗操作,去除URL中的配置数据,提取分析需要的字段。
数据匹配:通过Spark程序对清洗后的用户行为数据与汽车信息采集数据进行匹配,识别用户访问的汽车信息。
行为统计:统计用户对汽车产品的访问次数,计算其喜好程度(评分)。
机器学习:基于Spark-Mllib进行机器学习预测,预测用户潜在喜欢的汽车产品。
数据可视化:通过OracleDV对结果数据进行可视化展示。